
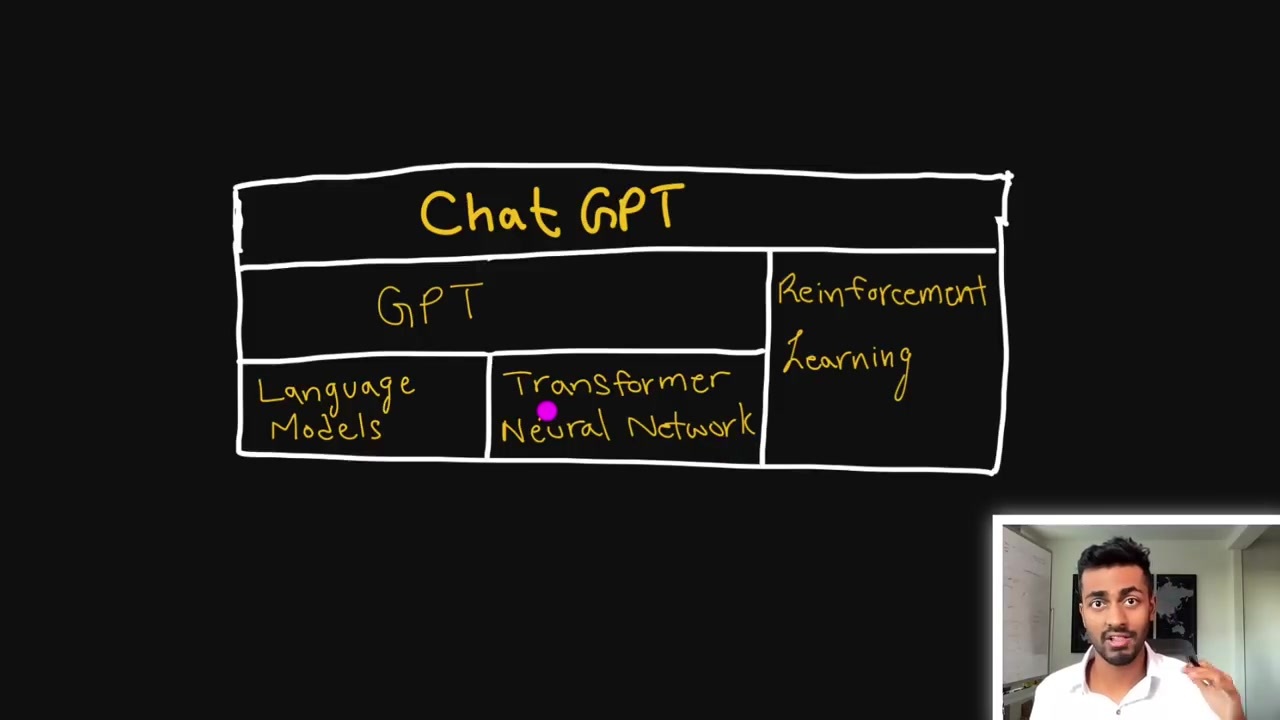
'Chat GPT'는 사용자로부터 입력된 문장을 이해하여, 적절한 문장을 생성해 주는 언어 모델이에요.
이 모델은 'GPT、강화 학습' 등의 이론에 기반을 두고 있고, 자연어 처리를 위해 제작된 모델로, 'Transformer neural network' 기술을 활용합니다.
또한, 이 모델은 부적절한 문장을 생성하지 않도록 할 수 있는 'non-factual / non-toxic' 필터링 시스템이 구현되어 있다고 해요.
이번 영상에서는 'Chat GPT'와 이와 관련된 기술들에 대해 소개합니다.
언어 모델은 수학적으로 언어를 이해하는 모델로, 단어 시퀀스의 확률 분포를 이해해요.
이 모델은 이전에 있었던 맥락이나 단어들에 따라, 다음으로 생성할 가장 적합한 단어 토큰을 결정할 수 있어요.
데이터 유형과 모델의 구조에 따라, 이 언어 모델은 단어 시퀀스에 대해 다양한 종류의 확률 분포를 생성할 수 있어요.
이 언어 모델은 질문 답변, 텍스트 요약, 언어 번역 등과 같은 특정 작업을 처리하는 데 사용될 수 있어요.
트랜스포머 신경망은 시퀀스를 입력받아 다른 시퀀스를 출력하는 구조로, 언어처럼 단어 시퀀스로 사용될 수 있어요.
트랜스포머 신경망은 인코더와 디코더의 두 부분으로 구성되어 있어요.
영어에서 프랑스어로의 번역을 수행하기 위해 모든 영어 문장의 단어들은 동시에 전달되고, 각 단어에 대한 벡터가 생성되며, 이 단어 벡터들은 디코더로 전달되어 프랑스어 번역을 생성합니다.
하나의 단어씩 생성될 때마다, 그 단어는 디코더에게 맥락으로 제공돼요.

이 아키텍처의 큰 장점은 언어에 대한 문맥적 이해를 갖는 encoder와 decoder 두 가지 구성 요소를 가지고 있어서, 일반적인 언어 모델을 기반으로 하는데에 활용될 수 있다는 것이에요.
encoder를 스택에 쌓으면, transformer나 BERT의 양방향 encoder 표현을 얻을 수 있고, decoder 부분을 쌓으면 generative pre-trained Transformer를 얻게 된답니다.
또한 언어 모델링에서 대표적으로 활용되는 GPT 모델의 ChatGPT는, 일반적인 언어 데이터를 기반으로 사전 훈련된 모델을 미세조정(fine-tuned)하고, 이후 적 reinforcement learning을 통해 모델을 더욱 뛰어나게 만들 수 있어요.
reinforcement learning은 보상을 통해 목표를 달성하기 위한 프로세스로, 에이전트가 최대한 빠르게 목표 지점에 이르도록 보상을 사용한다는 것과 관련됩니다.
ChatGPT와의 관계를 설명할 때 일반적인 예제를 들어 reinforcement learning에 대해 설명할 거예요.
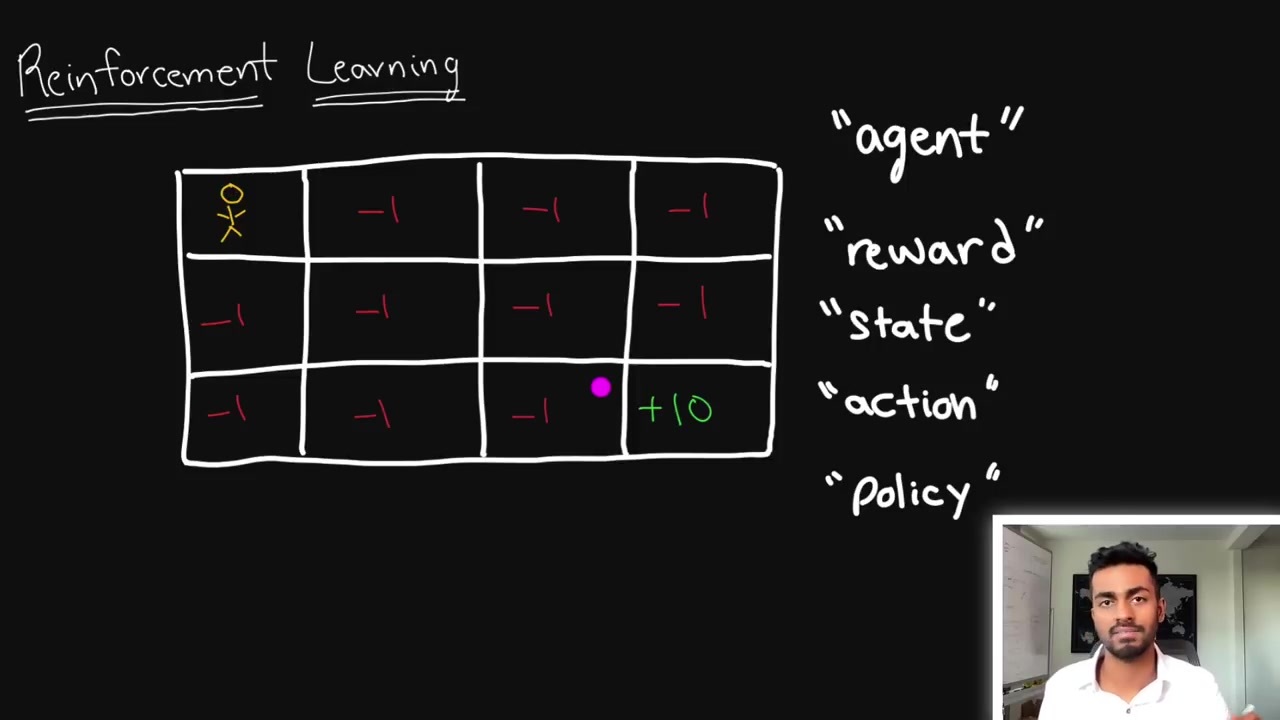
강화학습에서 상태, 행동, 정책에 대한 예시를 설명하고 있어요.
예를 들어 챗봇으로의 대입에서는, 챗봇 모델 자체가 에이전트이고, 챗봇의 대답을 기반으로 따지는 보상을 결정하여, 이로부터 모델이 보상을 최대화하는 적절한 정책을 찾게 되죠.
대답이 좋을수록 보상은 높아지며, 대답이 좋지 않으면 마이너스 보상을 받아서 강화학습에서 모델이 학습하게 되는 것입니다.
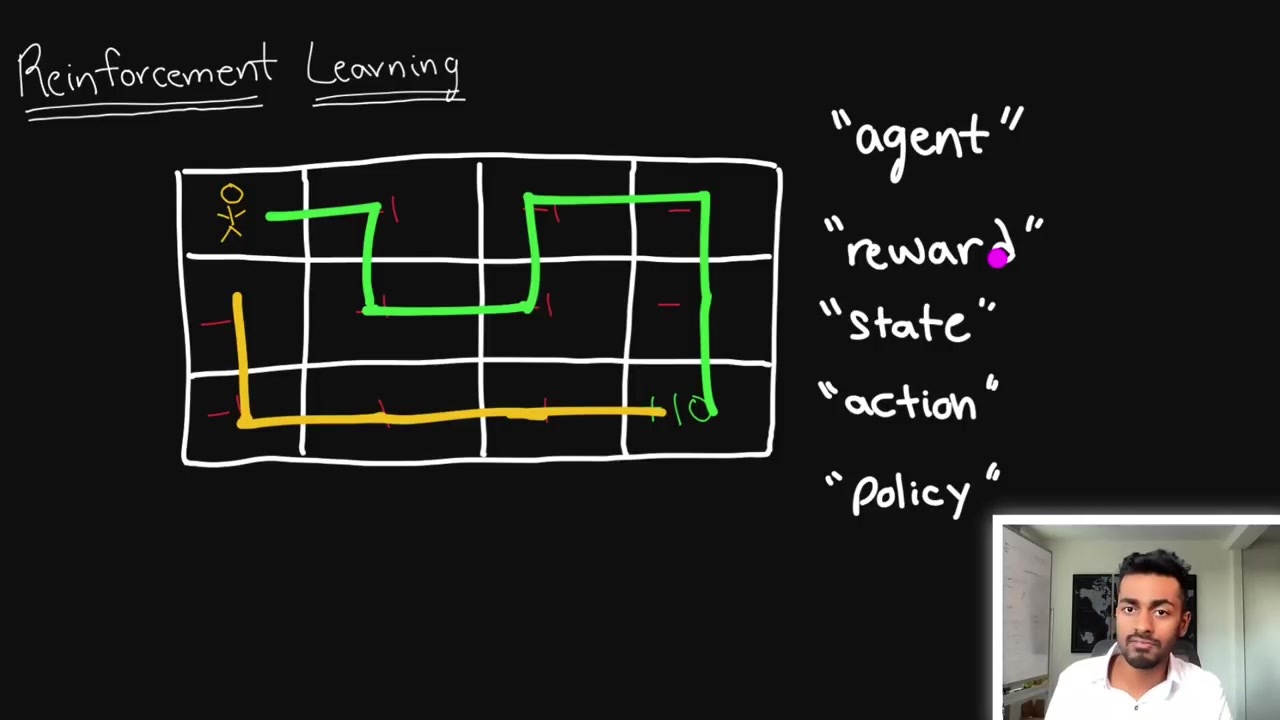
ChatGPT에서 각각의 에이전트가 취하는 모든 행동은 시간 단계 (time step) 로 볼 수 있어요.
상태는 사용자 입력으로부터 시작하여 이 시점까지 생성된 각 단어 또는 토큰을 포함하는 것으로 정의돼요.
이를 바탕으로 다음에 생성할 단어를 추론하며, 응답은 다양한 정책으로 결정되어 자체적인 보상을 받기도 해요.
모델을 보상을 통해 조정해 더 나은 응답을 생성할 수 있어요
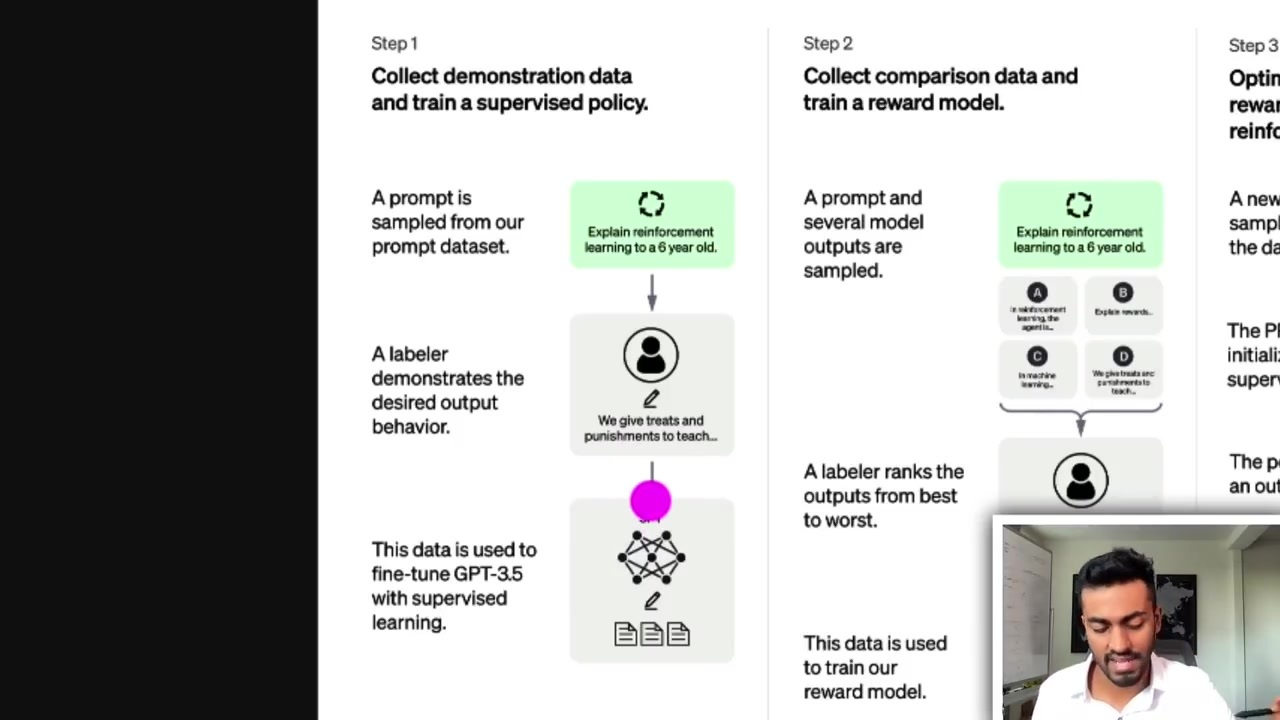
Supervised fine-tune 모델을 사용해 한 가지 프롬프트를 모델에 입력하고 몇 가지 응답을 생성하는 과정입니다.
응답의 품질을 레이블러가 순위 매기며, 각 응답에 대해 레이블러는 등급을 할당합니다.
이 등급은 rewards 모델을 학습시키기 위해 사용됩니다.
리워드 모델은 초기 프롬프트와 응답 중 하나를 입력받아 이 응답의 품질을 나타내는 리워드를 출력합니다.
이 리워드는 fine-tune 모델의 손실 함수에 사용되어 파라미터 업데이트를 위해 역전 파 됩니다.
이 프로세스는 비독성 행동과 사실적인 응답을 모델에 통합시키는 데 도움이 되며, 리워드가 이에 기반하여 생성되기 때문입니다.
모델에 리워드를 이런 식으로 통합하면, 모델이 덜 독성이고 더 일관되고 사실적인 응답을 생성하는 데 도움이 됩니다.
'AI, IT & 디지털정보' 카테고리의 다른 글
| AI와 로봇 시대, 직업을 유지하기 위한 방안은? (0) | 2023.12.03 |
|---|---|
| 미국 Odyssey에서 새롭게 등장한 AI 퍼터의 특징은? (0) | 2023.12.02 |
| 챗GPT로 데이타분석하는 7가지 방법 (0) | 2023.11.28 |
| 챗 GPT로 실제 수익 창출하는 5가지 방법 (0) | 2023.11.28 |
| 카카오톡 PC 버전 다운로드 방법 (0) | 2023.11.24 |



